A drone that holds three minds in parallel — and only picks one when forced to
CANavigator: instantiating the Conflict Architecture on a 3D UAV under simultaneous time, energy, and spatial constraints. 4,000 simulated missions. 34.55% faster. 34.52% less compute energy. Zero deadline violations.
Conventional autonomy pipelines force a single resolved output at every tick: one planner, one trajectory, one decision. Biology doesn’t work that way. A pilot pulling up to avoid a collision and a pilot routing around weather are doing two different computations, on two different timescales, with two different accuracy floors — and the brain runs them in parallel until the world forces a commit.
My M.S. thesis, defended at Virginia Tech in April 2026, is the first 3D UAV instantiation of the Conflict Architecture (CA) — a brain-inspired design that treats the speed–accuracy–energy tradeoff as a first-class structural property of the system rather than a tuning parameter. The testbench, CANavigator, ran 4,000 simulated urban search-and-rescue missions and produced a result that conventional architectures shouldn’t be able to produce: better on time and compute energy at the same time, while holding safety and physical flight energy constant.
This post is the why and the how.
The design principle: conflict is the resource
Every autonomous system has to answer the same question — what do I do next? — under three pressures that pull in different directions:
- Speed. Reflexes fire in ~20–50 ms. Deliberation takes ~300–600 ms. Neither pathway dominates categorically.
- Accuracy. A fast answer is allowed to be wrong in non-fatal ways. A slow answer has to be right.
- Energy. Compute costs joules. So does flight. They’re not interchangeable.
The conventional move is to pick one algorithm, tune it, and ship. That algorithm sits at one point on the speed–accuracy–energy surface and stays there — even when the environment changes underneath it. A reflex planner wastes the deliberation budget when it has one. A deliberative planner misses deadlines when the environment doesn’t give it one.
CA inverts the framing. Instead of resolving the conflict between fast/cheap and slow/accurate at design time, CA runs multiple heterogeneous Algorithm Processing Elements (APEs) in parallel, each occupying a different point on the surface. A Selector commits to the best completed output at the moment the environment forces a response. Conflict isn’t eliminated — it’s the substrate the system computes on.
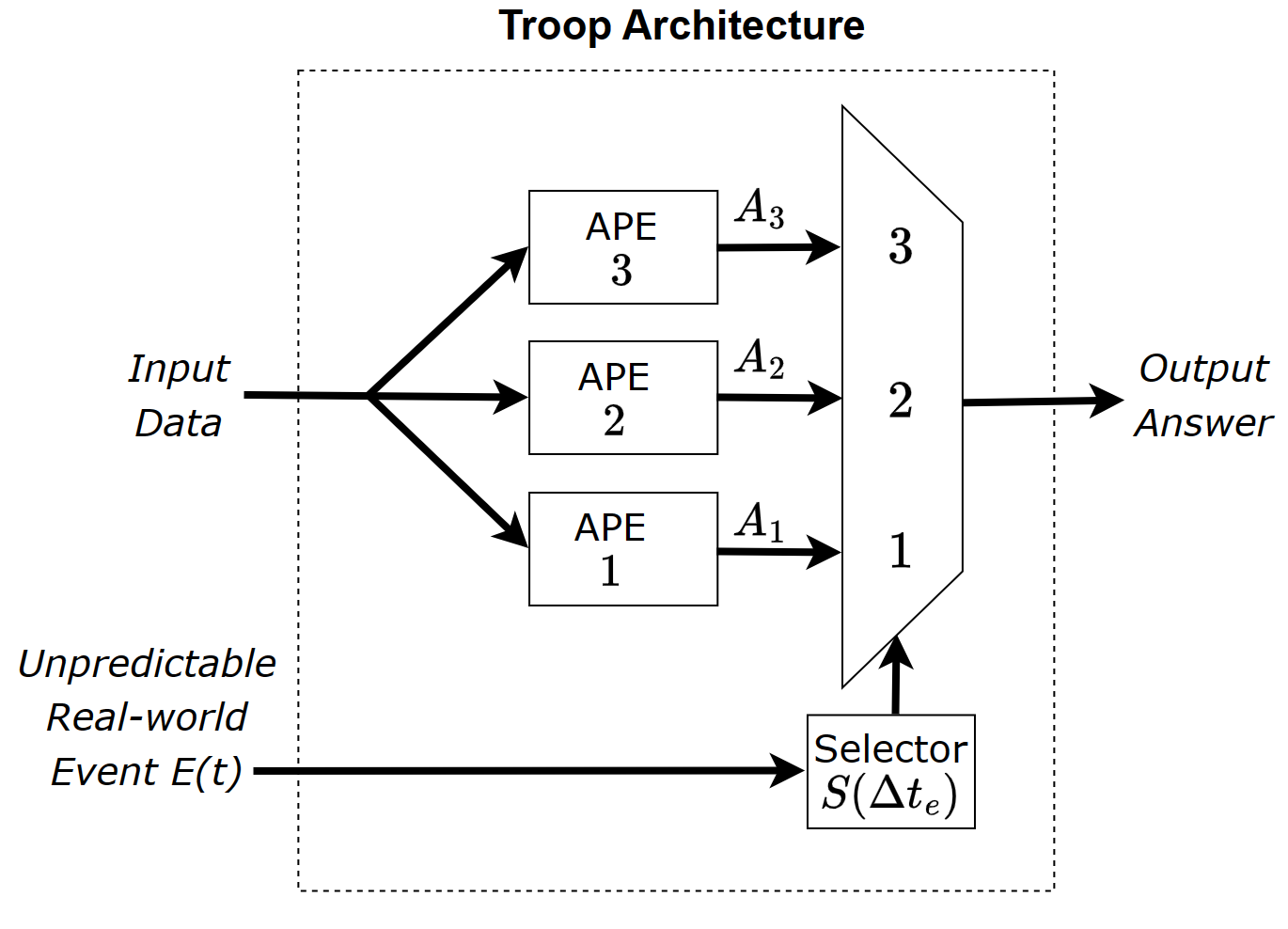
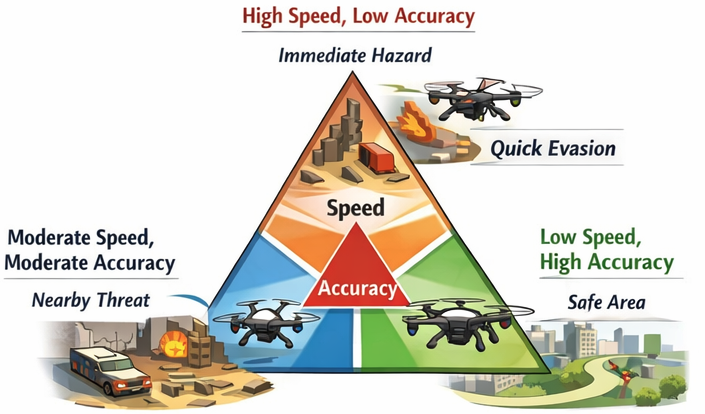
feasibility beats optimality. The winning response isn’t the most accurate one — it’s the most viable under whatever constraints the world just imposed. You can only pick that response if you were already computing it.
Why drone navigation is the canonical CA problem
For CA to be more than a clever idea, the problem class has to actually match. Autonomous aerial navigation in an urban search-and-rescue setting hits all four conditions simultaneously:
- Decisions are forced by the environment, not the algorithm. Obstacles, wind gusts, and no-fly zones arrive on their own clock. There’s no time to converge.
- Multiple structurally distinct strategies exist, but none dominates. Reflex avoidance, reactive corridor-following, and deliberative heading search each win on a different subset of situations.
- Success is binary. A drone that misses a deadline by 1 ms and hits a wall fails identically to one that misses by 1 s. Feasibility under physical constraints, not theoretical optimality, is what counts.
- The environment keeps changing while you’re still deciding. By the time a slow planner finishes, the world has moved on.
That’s the CA problem class. Drone navigation isn’t an analogy for it — it’s an instance of it.
The three APEs
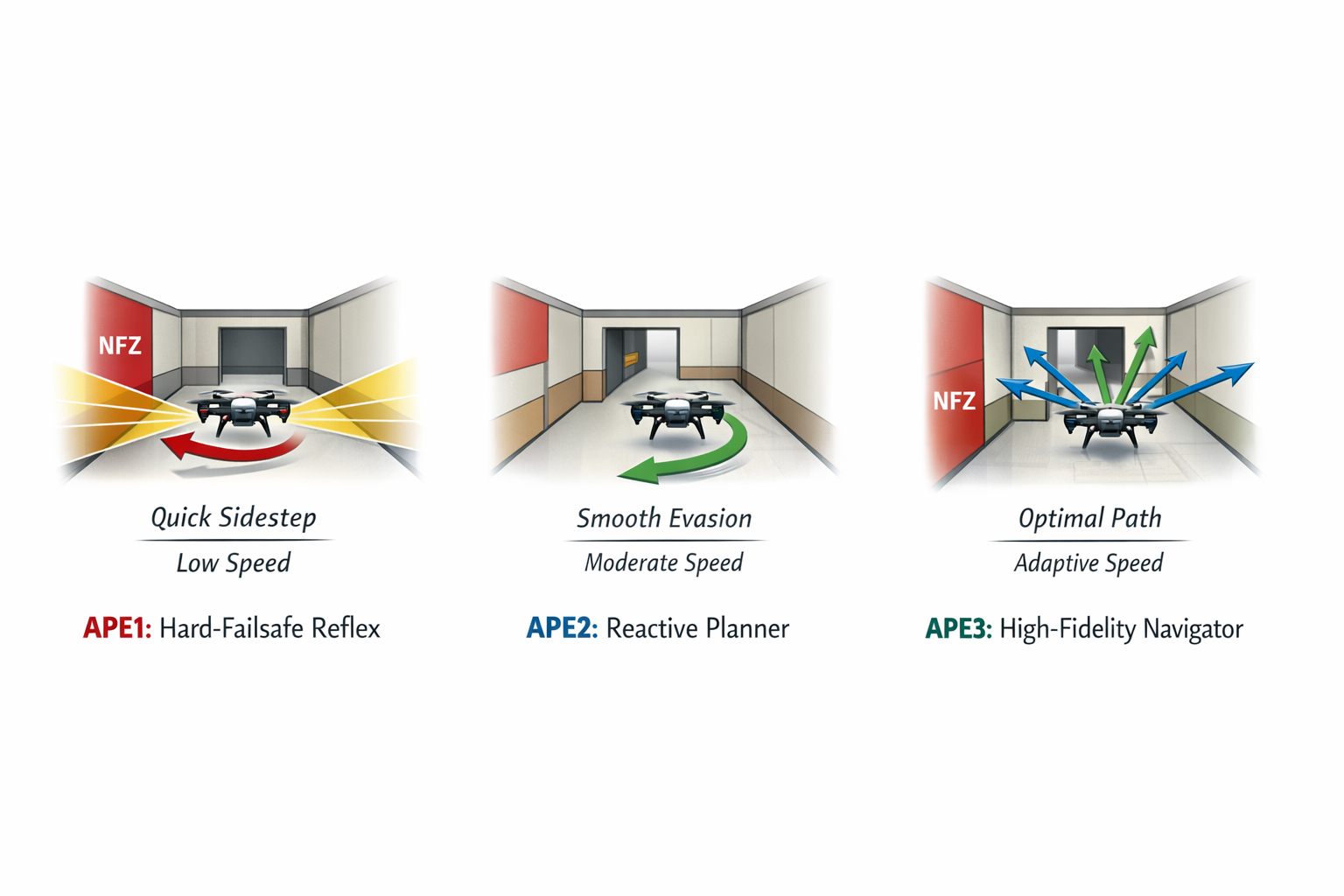
CANavigator instantiates three APEs on a single canonical input (LiDAR + pose), each occupying a deliberately different point on the tradeoff surface:
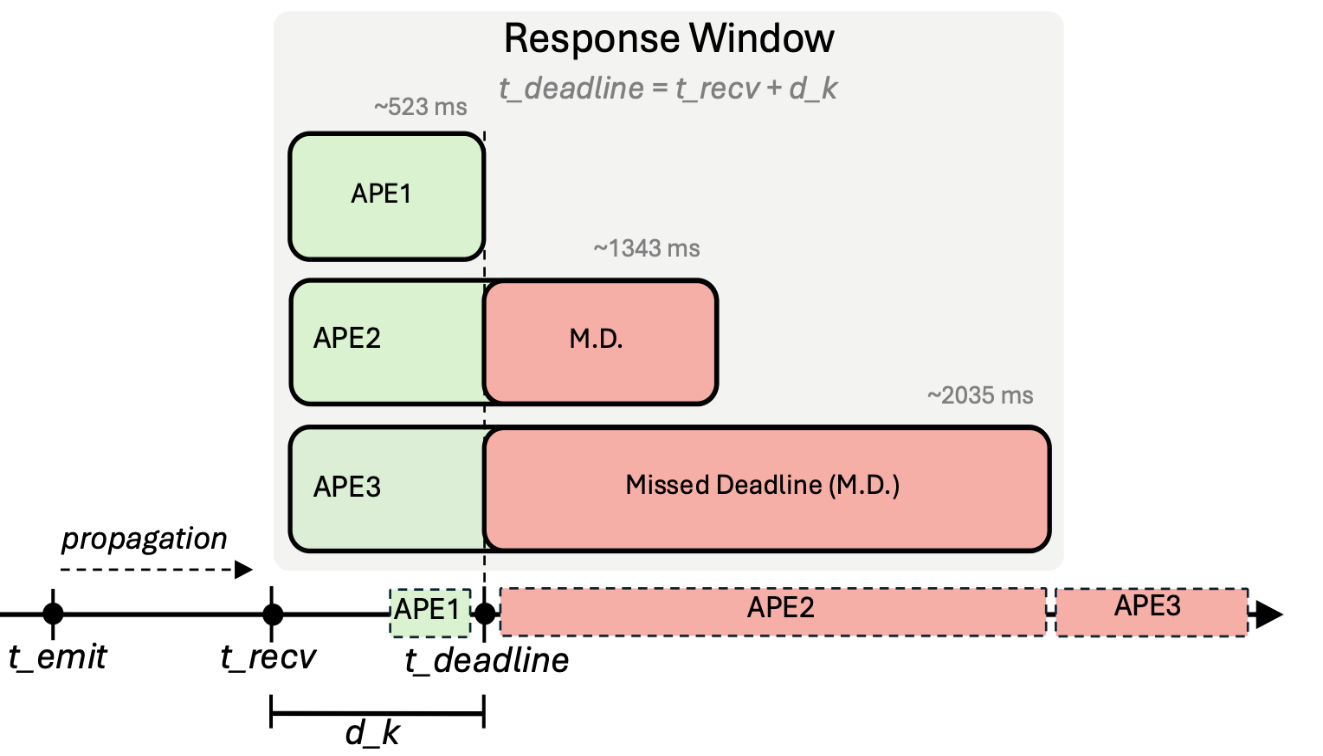
- APE1 — Reflex (≤523 ms). LiDAR clearance asymmetry. Sub-millisecond core compute. Always completes before deadline.
- APE2 — Reactive (≤1,343 ms). Corridor geometry plus side-bias memory. Moderate compute cost.
- APE3 — Deliberative (≤2,035 ms). Full 360° heading sweep with no-fly-zone scoring. Highest navigation quality. Highest compute cost.
Latencies were derived from ARM Cortex-A78AE cycle counts on a target NVIDIA Jetson Orin NX 16GB (8-core, 2.0 GHz, 25 W TDP), scaled 1,000× to absorb realistic LiDAR + ROS 2 pipeline overhead.
The critical structural fact: APE1’s 523 ms budget sits below the 0.90 s inter-event floor. Events arrive log-uniformly every 0.90–4.00 s with hard deadlines — and APE1 is guaranteed to complete inside the tightest possible event window. Deadline compliance for CA is therefore architectural, not statistical. The Selector always has at least one completed output to fall back on. APE2 and APE3 are pure upside: when the next event happens to arrive later than 1.3 s or 2 s, the Selector gets to choose a higher-fidelity answer.
The testbench: CANavigator

The experimental claim is that CA simultaneously improves time and compute energy under realistic physics. That’s an extraordinary claim, and it demanded a testbench built for honest measurement:
- Gazebo simulation of a 200 m × 100 m Manhattan grid with axis-aligned no-fly zones. Rectilinear geometry deliberately eliminates planner-specific geometric advantages — no planner gets to be “good at curves.”
- Procedural generation from a master seed. Same seed → same arena, across all four strategies (APE1, APE2, APE3, CA). Cross-strategy comparisons sit on identical worlds.
- 2nd-order actuator dynamics with jerk-limited acceleration. No idealized instant response.
- Aerodynamics: linear + quadratic drag, per axis.
- Wind: Ornstein-Uhlenbeck process — stochastic but temporally correlated gusts, not white noise.
- 1,000 runs per strategy. 4,000 runs total.

The hard part wasn’t running the experiment. It was making the measurement trustworthy.
Four design challenges that shaped the testbench
1. Temporal domain mismatch. Mixing wall-clock and sim-clock silently corrupts elapsed-time data, and the corruption is invisible until post-run analysis. Fix: all timing in the navigation stack is governed by the ROS sim clock only. Nothing on the navigation path ever subscribes to wall time.
2. Joint energy modeling. No standard metric captures compute energy + flight energy together. Fix: derived a composite model from first principles. Compute energy = per-APE CPU active time × Orin NX power model. Flight energy = horizontal displacement × empirical energy-per-meter (EPM = 208.9 J/m, calibrated against the DJI FlyCart 30 baseline). The two are tracked and reported separately so the strategies can be compared on the same axes.
3. Shared pose coupling. Async timestamp skew across four strategies compounds into statistically unreliable cross-run comparisons. Fix: a Pose Republisher mediates all pose access. One canonical stream. No strategy ever reads Gazebo directly.
4. Measurement perturbs the loop. Active observers alter the real-time behavior they’re trying to measure. Fix: the testbench is structurally read-only. All energy accounting and deadline-violation analysis happens post-execution from passive logs — never inline. The arbitration loop being measured never sees the measurement.
Each of these is the kind of bug you only notice if you’re looking — which is itself a thesis about how to evaluate architectures honestly.
What gets measured
Five metrics per run, all derived post-execution:
- Mission elapsed time (sim-time duration from start to target arrival)
- Algorithmic compute energy (per-APE CPU active time × Orin NX power model, accumulated)
- Physical flight energy (horizontal displacement × EPM, derived from pose logs)
- Violation rate (any missed deadline — in the real world, a crash)
- No-fly-zone (NFZ) violations (spatial breaches)
Across 4,000 runs, the experiment generates ~132,000 structured log entries per pass (~74.5 MB of telemetry). The 1,000-run sweeps take between ~1h 7m and ~57h 33m of wall time, depending on strategy. That asymmetry is itself data: slower strategies don’t just produce slower missions, they produce slower experiments.
The result that shouldn’t happen
The headline numbers are uncomfortable for conventional architectures, because they look like a free lunch.
First, the feasibility filter — elapsed-time numbers alongside deadline violation rates:
| Strategy | Mean elapsed (s) | Median elapsed (s) | Std. dev. (s) | Event violation rate |
|---|---|---|---|---|
| APE1 | 59.56 | 68.82 | 27.66 | 0.00% |
| APE2 | 34.70 | 29.80 | 16.86 | 28.02% |
| APE3 | 33.89 | 28.62 | 18.88 | 40.39% |
| CA | 38.98 | 35.39 | 17.78 | 0.00% |
APE2 and APE3 look fastest on paper — and that’s the trap. At scale, both miss deadlines often enough that their “speed” is an artifact of incomplete missions, not better performance. A planner that crashes 30–40% of the time isn’t fast; it’s broken. APE1 and CA are the only two strategies that achieve 0.00% deadline violations across 1,000 runs — APE1 by reflex, CA by guaranteed fallback to APE1. Everything below compares those two.
Then the full picture across all metrics:
| Strategy | Mean elapsed (s) | NFZ violations | Compute energy (J) | Physical energy (J) | Event violation rate |
|---|---|---|---|---|---|
| APE1 | 59.56 | 0.576 | 148.92 | 38,432 | 0.00% |
| APE2 | 34.70 | 0.611 | 86.76 | 39,249 | 28.02% |
| APE3 | 33.89 | 0.653 | 84.75 | 39,340 | 40.39% |
| CA | 38.98 | 0.563 | 97.51 | 38,922 | 0.00% |
Statistical significance: p < 0.0001 across the 4,000-run population.
Speed and energy efficiency are supposed to be in tension. Moving faster usually costs more compute. CA improves both by ~34% simultaneously. The mechanism: CA engages expensive pathways (APE2, APE3) only when the cheap pathway (APE1) has slack to spare. When time is tight, it commits to the reflex. When time is loose, it commits to a better answer — and the better answer is decisive enough that the mission ends sooner, recovering more energy than the deliberation cost.
This is Pareto-improving arbitration. CA strictly dominates APE1 on time and compute energy without paying anywhere else. The radar chart makes the shape obvious — CA’s contour sits inside APE1’s on the two metrics where lower is better (compute energy and elapsed time), and overlaps it on the two where parity is the goal (NFZ violations and physical energy):
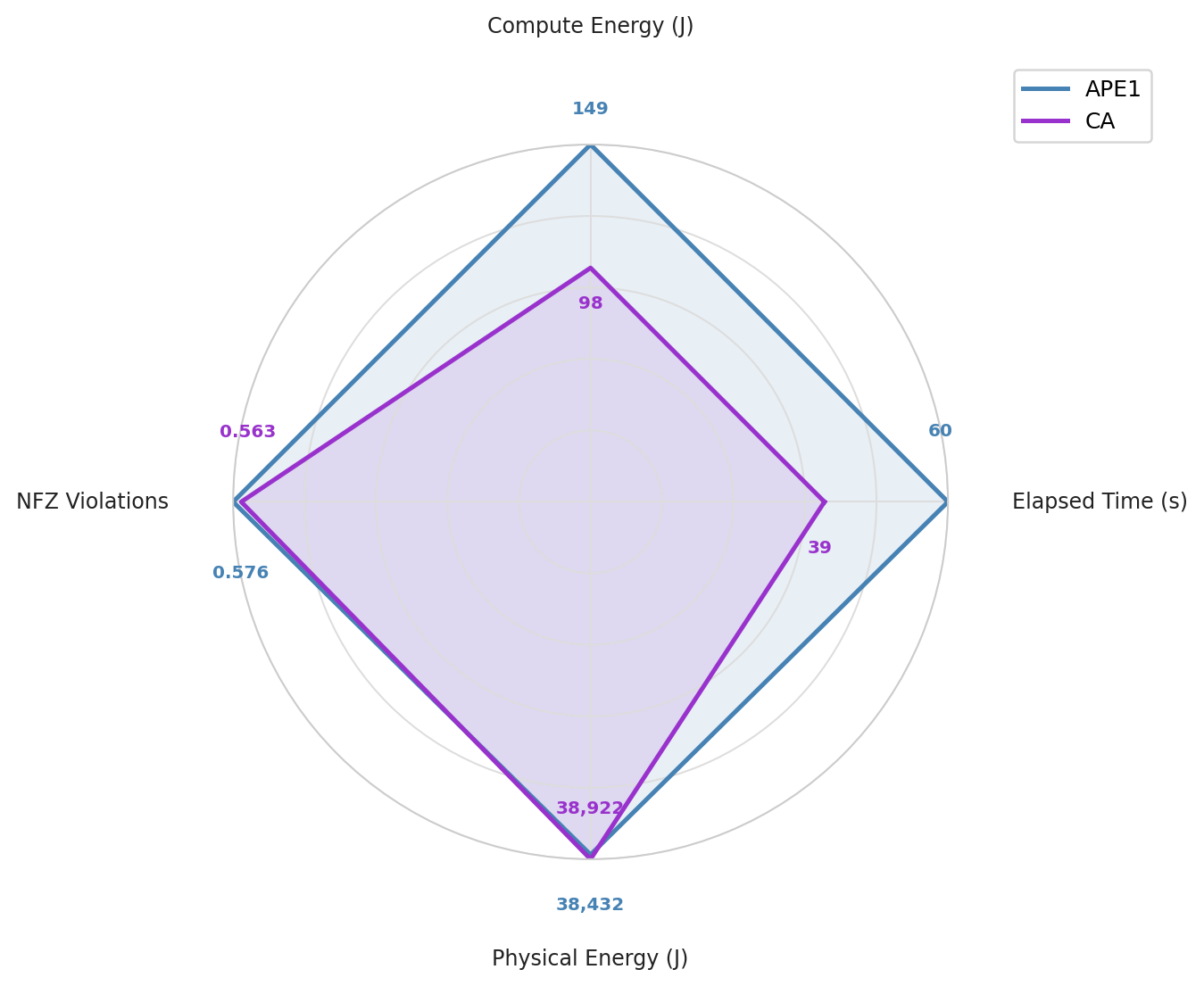
This is the result that makes CA a real design principle rather than a clever heuristic.
the standard intuition is that running more algorithms costs more energy. CA runs three and uses less, because the Selector lets the system stop computing the moment a usable answer exists. Parallel speculation beats sequential commitment when the environment is the one holding the clock.
What this actually contributes
Stripping away the experimental machinery, the thesis makes five claims I’ll defend in writing:
- The Conflict Architecture has a problem class, and autonomous aerial navigation is in it. Environment-forced decisions, multiple non-dominated strategies, binary feasibility, non-stationary world. CA isn’t a universal hammer — it’s the right tool when those four conditions co-occur.
- First 3D UAV instantiation of CA under simultaneous time, energy, and spatial constraints, validated across 4,000 runs.
- Algorithmic computation energy as an explicit CA evaluation dimension. Prior CA work measured time and accuracy. Compute energy is a first-class axis here because on a real drone, joules are joules — burned in the CPU or burned in the rotors, they come out of the same battery.
- First evidence of Pareto-improving CA arbitration (p < 0.0001) on multiple metrics simultaneously.
- CANavigator itself — a ROS 2 / Gazebo testbench purpose-built for honest multi-constraint CA evaluation, with the four measurement disciplines above baked in.
What’s next
The thesis closes a loop, but it opens four more:
- Hardware deployment. Everything above is simulated. The next step is a physical quadrotor with the same APE stack on Orin NX silicon. The simulation already targets Orin NX latencies, so the port should be informative rather than surprising.
- Wider APE design space. Three APEs is the minimum non-trivial instance. Finer-grained tradeoff points — and neuromorphic APEs in particular — would let the Selector exploit compounding efficiency gains as the spectrum gets denser.
- Adaptive APE management. Right now all three APEs run on every tick. A battery-aware Selector could suspend APE3 during low-battery mission phases and revive it during loiter — energy savings without architectural change.
- Broader domains. Medical delivery, aerial patrol, multi-agent coordination, degraded sensing. Each one stresses the CA problem-class boundaries differently.
The deeper bet under all of this: most autonomy bottlenecks aren’t algorithm bottlenecks — they’re commitment bottlenecks. Conventional systems are forced to commit to a single computation before the environment has finished telling them what it needs. CA defers commitment to the latest physically permissible moment, and uses the intervening time to compute several answers in parallel. The drone doesn’t have to be smarter. It just has to be allowed to hold more than one idea at once until the world picks for it.
That, at 30,000 feet, is what the brain does. Now it’s what CANavigator does too.
Source: github.com/Vikhyat-Chauhan/CANavigator · Defense: 28 April 2026, Virginia Tech, advised by Dr. JoAnn Paul.